


Nonprofit Data Analytics - Dysfunction with No One to Blame.
An entertaining summary of the data issues I faced at a behavioral health nonprofit along with a guide on how to solve them.


Data Analytics for a Nonprofit
The fascinating story of how one simple request demonstrated the complete dysfunctionality in data collection, data management and general technological understanding of several nonprofits and my attempt to solve it. (Details have been changed for identity and drama purposes).
Our nonprofit, which I’ll call Sunrise Wellness (thanks ChatGPT) asked me to develop a report to help answer the following question.
Do patients prefer to see therapists of the same gender and native language?
Seems pretty simple, right? Get a breakdown of all the genders and spoken languages for the therapists and patients and send that in. Well, simple it wasn’t, because immediately I ran into several problems. Problems, by the way, I also discovered weren’t only specific to Sunrise Wellness…
Table of Contents:
Problems:
Operational and Technological
Operational:
Lack of Technical People: To start, I was the fish-out-of-water/black-sheep/nerd-foreigner trying to communicate technical information to a group of therapists, who were, for all intents and purposes, basically Amish in their technological savviness. Experts in people? Yes. Experts in computers? Keep em far away.
High Turnover: The turnover rate for admin staff was so high that within the first 4 years not a single person who worked in leadership was left. Not one. In fact, over a 6 year period, we went through four different CEOs. This meant my fish out of water problem was way worse. Frustrated admin staff hid information from one another, afraid they were next on the chopping block after being left to clean up the messes of previous leadership. How the he** was I supposed to gather information on data collection and storage when everyone was desperately trying to stay hidden from view? Worse, well meaning and hard working people were terrified of data, because it had previously been used against them. This clinic often felt like a car wash you might find on the rougher side of town. People went in and out but no one would pay attention as long as there’s money in the business’s hands at the end of it. The “active” status for clinicians was about as meaningful as the “active” status for patients. In other words, “It could be they’re active, it could be they’re not. Last we checked, which was about 6 months ago, they were, but who knows now.”
Mismatched Data (or the Who’s Who problem): This problem is so underrated, it’s hard to describe.
The gender data for our 3000+ PATIENTS was stored in our EMR (Electronic Medical Record software. A website or application where medical information is gathered and stored). But the gender data of our 500+ THERAPISTS was stored in a totally different location! Therapist gender was stored in two COMPLETELY DIFFERENT HR platforms which did not “talk” to our EMR in any way shape or form and did not have a workflow crossing users over from one platform to the other.
As an example, the same Sunrise Wellness therapist’s name on our EMR was Rachel Smith, but on our HR Platform was Hannah Martin! The same person! It was so bad that initial attempts to match people in both software based on names (because it was the only possible common factor) were more than 80% off! First and last names were spelled differently across platforms, therapists who got married and changed their last names, only got married in one program, some had middle initials some didn’t, and some put their middle initials in the first-name field while others put it in the last name field.

Besides for all that and worse still, data on the therapists’ preferred language was collected on paper! Paper, I tell you! With all that, the only redeeming factor was the level of automated access I was given. The two software we used for our HR portal and for payroll (why we have both, don’t ask), gave me live access to the data I needed. Bless them, both had easily interactable APIs (Application Programming Interface. Basically, a way to interact with the software through programming and automation).
No Mentorship: Here I was sitting on a local computer, by myself, with no access to resources or mentorship. Our IT guy (yes, we only had one IT guy for our 600+ employees and 7 different physical locations) had no programming experience and no time to discuss issues. On numerous occasions he could be seen on the phone with two or more people AT THE SAME TIME! I frequently found myself waiting weeks and even months for answers to questions and even then wouldn’t get clear information. I remember once asking him how he would approach an access related problem, and after several weeks of waiting for a reply, I got the following answer, “Done”. Nothing had changed and I was no closer to understanding the solution but somehow it was “Done”.
I spoke to several other similar nonprofits in the hopes of finding some mentorship, advice, best practices, or suggestions. Instead I found myself being innocently reverse interrogated about which software I was using, my best practices, and how I structured my environment because it turns out that many of their “data experts” were basically good with Excel and that’s it.Poor Data Collection: Data regarding patients’ gender was a free form text box. Since a lot of our staff’s first language was not English, I would see things like “Mail”, “M”, “Femail”, “Christian” (Not sure how that one got there) etc. Worse, it was collected in a totally different part of our EMR depending on the director of the program. Yes. Depending on the director of the program. Each director had their own workflow for demographic data entry. Some would capture gender during the intake and some would capture it during the first phone call with the patient. This meant that the backend location of the data was totally different for each workflow and I had to spend hours searching for it. Imagine searching through every type of google form that’s been sent out to your 50,000 clients in the past 20 years looking for the ones containing some form gender.
Worse, some Directors would collect gender on spreadsheets, and some on paper! This meant I had to go request permission from each director individually to access their spreadsheets! Spreadsheets, mind you, that were frequently outdated and did not contain patient ID numbers for me to connect back to our EMR! (If you’d like to understand why data collection was so bad you have to understand one of the primary driving forces behind clinics in general. Audits. Audits will push clinics to collect data for different initiatives. But then only for those initiatives. Because regulations differ per program, I often see two patterns in data collection issues:Data is only collected for the programs under regulation even if it may be useful across the entire organization.
If people don’t believe in the regulation itself, the data is often collected in a half-a**** manner. So it will be rushed, without much thought put into the collection process.)


Technological:
Limited Data Access: For the majority of our patients we had a cloud hosted EMR. Most cloud hosted EMRs, at the time of this writing, don’t give automated access to data. Our EMR, Na We Wont Do It Inc., was no different. After a lot of begging and pleading they finally provided a solution. Long story short, they decided to store a copy of the data in an Azure Analytics database that was refreshed once a day. (For the people interested in the technical piece, an Azure Analytics DB is a read-only database that accepts DAX, MDX, and a couple of other languages for querying. We only care about DAX for reasons I’ll talk about later). Sounds nice until you realize that the database is not made to be queried.
But why couldn’t they give me direct access to what was, after all, OUR DATA? Why? Because Na We Wont Do It Inc. had brilliantly designed their software so that EVERY SINGLE CLIENT WAS RUNNING OFF THE SAME SERVER. Don’t get me started on the number of issues this caused but, in short, giving me direct access meant risking access to other clients data so instead I got the once-a-day refreshed version. Not the best, but workable. (I personally had to design and build a data pipeline that authenticated with Microsoft, encrypted a connection and then streamed a copy of the data onto our server because Na We Wont Do It Inc. wouldn’t tell me how to do it. Complete transfer of the 120 tables into a local SQL database took about 50 minutes.)
Too Many Sources for the Same Thing: This is similar to the “who’s who” problem but with patients. If you have more than one EMR for patients, which we did, how am I, the data guy, supposed to know if our client, “John Smith” in Na We Wont Do It Inc. is the same as our client, “John Smith” in Some Other Dysfunctional EHR Inc. It’s not like John Smith is a common name or anything… And no, the platforms don’t talk to each other either, surprise surprise.
Badly Structured Data: Very technical so feel free to skip: Data was often structured in ways that made it difficult to aggregate. This is hard to describe and is easier to understand when accompanied by a visual (See below), but I’ll do my best. Many questionnaires and custom dynamic forms are structured in the backend as follows: Each row is one entire questionnaire with each column labeled with each of the questionnaire's questions. While this is understandable and intuitive for most users, from a data structuring standpoint there is a crucial piece missing here. The questions and answers aren’t labeled individually. This makes it difficult to aggregate because it requires explicitly calling each column. Once the structure has been fixed you can code something like “count the number of patients for every question and answer” easily. Some of Na We Wont Do It Inc.’s backend tables were even more discombobulated, but I would have to write another extremely boring article to describe that and I’m not going to.
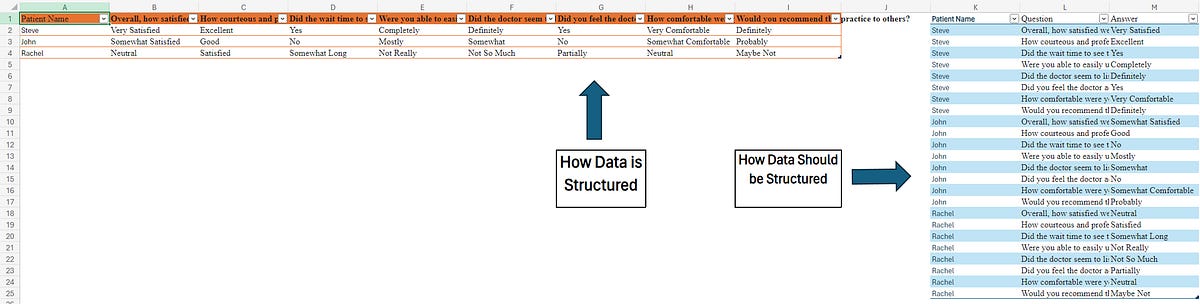
Don’t Get Me Started: And don’t get me started on the data that just wasn’t collected at all. Although by now, it might be too late for me to say, “don’t get me started.”
So, to say that I had my work cut out for me, would be the understatement of the century. But the solution I presented (to myself because there was no one else in my department nor anyone else in the organization technically savvy enough to understand) four years and a million YouTube videos later, I believed would help significantly solve the problems. And, in fact it did.
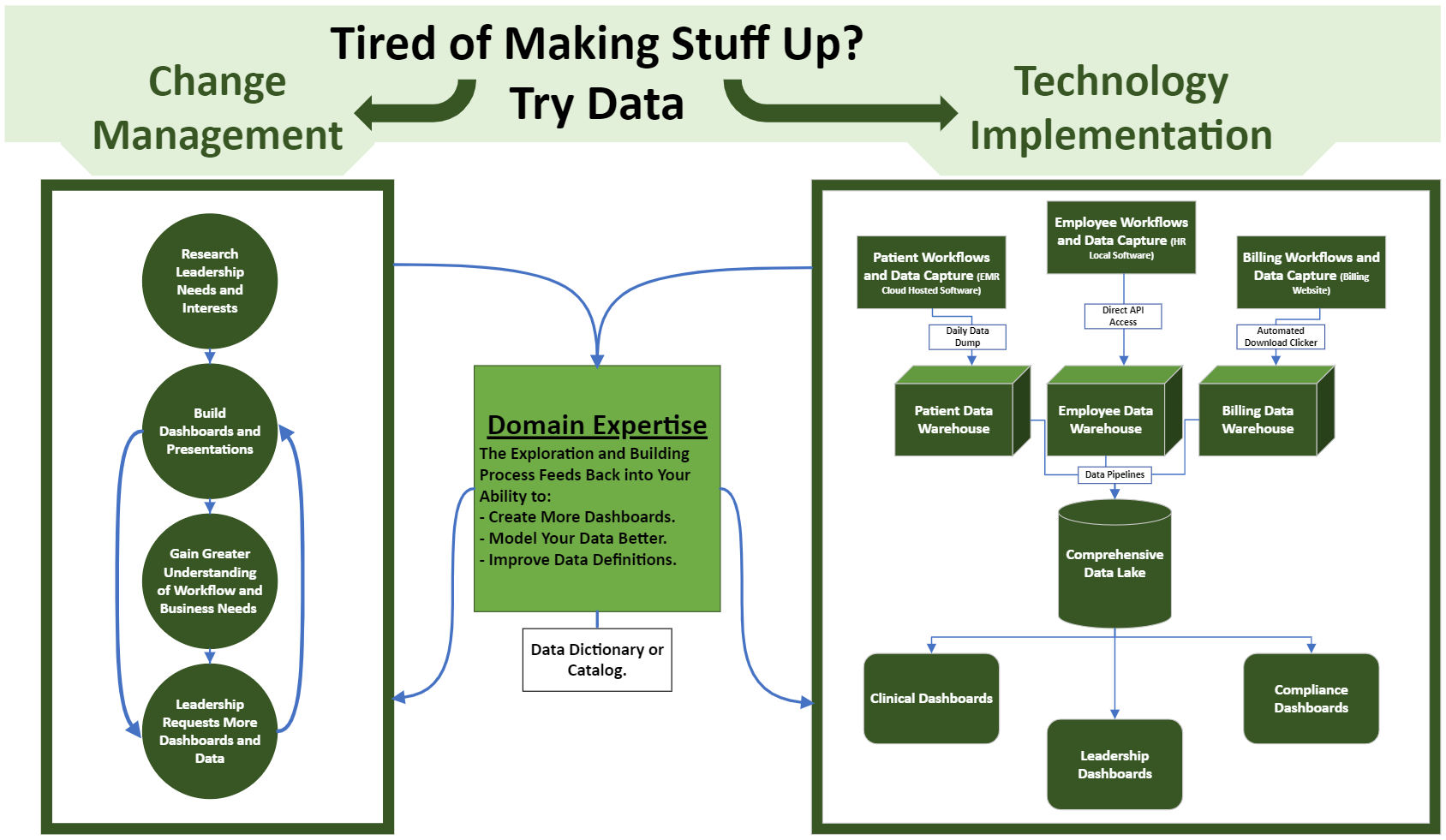
Solutions:
Change Management and Technology Implementation
Change Management:
Leadership’s Unspoken Problems: First and foremost, my biggest problem was the Sunrise Wellness politics. I had to deal with a mess of directors, workflows and leadership turnover. I needed buy-in, interest and information from the overwhelmed people at the top. Even the simple gender to patient matchup request required political maneuvering because people wouldn’t give me access to the spreadsheets where that info was captured. So I started doing a little digging. We were audit driven, so I asked what their biggest compliance worries were. We often applied for grants, so I took a look at the data points we used in applications. We were having trouble tracking denials, so I explored the financial data structure. We had an internal newsletter that always wanted to include good news so I asked directors for good news and explored how it was reflected in the data. Then I built dashboards or short presentations for them. And guess what. They wanted more. They went from no interest in data, dashboards, numbers, etc. to having 6 active dashboards, used by 20 different people in the span of 6 months. Even with all the insanity going on.
It’s Circular: The more I gave them, the more they gave me. Because of their new interest in data communication opened up. I was able to slowly develop a strong understanding of the clinical and business workflows and they were willing to change workflows so we could fix issues like mismatched data. That, in turn, fed back into the quality and number of reports and dashboards I was able to develop. Which, in turn, increased the number of dashboard and data requests.
Domain Interest: Lucky for me, I like psychology and therapy so I would participate in clinical trainings and surprise people with my understanding of some of the classic modalities like CBT, DBT, EMDR, etc. I was able to display the usefulness of having a programmer around by being generally involved and doing random, less data oriented, projects. I found little ways to automate projects that were previously done manually. I aimed to restore trust by being as transparent as possible in all my interactions (My personality is to wear my heart on my sleeve which made it a little easier). This was a slow process but effective. Apparently, someone prior to me, let’s call him William, had taken a more forceful approach and was quickly shut out by all the department heads (William quit). Honestly, it’s amazing it worked at all if we compare the simplicity of the approach to the complexity of the problem. In short, read How To Win Friends and Influence People by Dale Carnegie.
Volunteer: Every day, I felt like I was volunteering for a suicide hotline (I’ve done that before so I know what it’s like). Juggling leadership’s intense emotions, paranoia, and generally juggling the egos of powerful people with the technological knowledge of a two year old, left me drained and exhausted. Honestly, the amount of irony working for this mental health clinic goes beyond description. I highly recommend seeing a therapist.
Work Support: Despite all of this progress, the truth is, I should have given up. But I didn’t and, I have to mention, it wasn’t solely because of my brilliance and persistence (although I worked freakin’ hard so I’ll take some credit). I’ve spent my whole life struggling with social anxiety and tend to be a people pleaser. Working for Sunrise Wellness in such a politically charged environment made that so much more stressful, and I made many mistakes. But despite the tumultuous administrative situation, I had enough co-workers and bosses who made my life worth living and kept me going and motivated to continue. Without the pushing of some similarly minded leadership I would not have succeeded.
A Word of Warning: I was obviously frustrated at the resistance I encountered throughout this process and I’ll admit, I was tempted numerous times to use the data against them. Force them, by virtue of numbers, to listen. But that’s a mistake I made once which I don’t plan on repeating. That incident is etched deep in my mind.
The administration, located on the 3rd floor of our building, was so hated by the clinics, the term “3rd Floor” was used as a slur and usually accompanied by an exaggerated roll of the eyes. I, the data analyst from the 3rd floor, had gone to a director to talk about his clinic’s number of overdue session notes. Let’s call that director Johnny. The conversation went as follows:
“Who’s asking you to make this?”, Johnny questioned me when I showed him the dashboard.
“Nobody, I just figured it was information you’d like to know”, I responded.
Suspiciously glaring at me, he said, “It’s the 3rd floor isn’t it?”.I was a little more nervous now, “No, I thought it was a number you cared about because” and, seeking to regain control of the conversation I made my first mistake, “legally we’re required to have those notes done sooner.” I thought I was being passive aggressively clever. But I had forgotten I was working for a mental health clinic where passive aggressiveness was basically straight aggression.
“You don’t know what I have to put up with and the messes I’ve had to clean. The clinicians are not ready for this." Johnny responded firmly, and then immediately returned to his original line of questioning. “It’s Rachel (the newly hired CEO) isn’t it?”
So I made my second mistake and went for more pointed aggression. “No it’s not. But regardless, you’re the director. Make them do it. They’re not children and we’re paying them to get it done on time”.
“Steve, you don’t know what you’re talking about. We’ll discuss this some other time.” Johnny said angrily, and walked away mumbling something about the “3rd floor” having their heads stuck somewhere I’d rather not say in this article.
And here is where I made my third and final mistake. The administration had been pretending that everything was hunky-dory and their relationship with the clinics was just fine. I intended to change that. So I went to leadership and repeated the conversation I just had, while leaving out the director’s name (I was foolish enough to think that was a good safeguard).
It’s painful for me to describe the damage I caused and relationships I had to rebuild as a result, but the next couple of days was filled with more passive aggressive conversations than I can describe (Clinic Directors, being clinicians themselves, aren’t very good at straight aggression). The result. My access to Johnny’s spreadsheets slowly disappeared along with my relationship to him.
So my message is, don’t make the same mistake I did. It’s not worth the headache or heartache. I promise. This is probably the kindest, most well intentioned field in the USA. If the words behavioral health nonprofit tells you anything it’s that they’re certainly not doing it for the money. Meaningful change won’t come about from aggression, even if it’s passive aggression. So have patience.
Technology Implementation:
My overall goal was to achieve the data gold standard. Build a single, well documented database as our “source of truth” which would combine our various disparate datasets and then run all our dashboards and reporting off that. For those interested, we’ll get into the technical details.
Tools:
Python and SQL: Utilizing a programming language vastly increase our analytical capabilities because it allowed us to automate reports and access data that was previously difficult to access. The primary tools we used on the backend for data manipulation was python, specifically the pandas library (although I’m told PySpark is more ideal) amongst others and SQL. My preference was to aim for reproducibility over speed. So whichever tool gave me the most easily readable code, was the one I chose. Ideally, PySpark would be used for any additional features/fields/columns that you want added into a database because it lazy-loads tables in (meaning it only loads the part of the table you’re manipulating into memory rather than the entire table like pandas, and can easily distribute the processing across multiple machines, improving speed and efficiency) But for now, we were using pandas because of readability, a strong ability to perform complex operations, and some roundabout options to improve speed (you can have operations be performed by your GPU, significantly improving performance). Regardless, its speed and flexibility compared to Excel cannot be understated.
Power BI: The primary tool we used on the front-end for graphing, dashboards, and general reporting was Power BI. Power BI utilizes the DAX language under the hood (Which is why I mentioned preferring DAX earlier when building out the data pipeline) and has the classic Microsoft drag and drop features for graphing. Dashboard development usually requires some back and forth with the client. Understanding where the data is captured in the workflow and what’s important to the client requires a significant amount of questioning and experimenting. A key point here is, “A lot of what is obvious to them may not be so obvious to everyone else.” As an example, I was once asked to do a report on depressionary screeners. At the time, I was unaware that there were different screeners for adults and children so my initial report missed all the children. To them, both were an obvious need because they were experts and had been using both depressionary screeners for so long they didn’t think to mention it. But to me, I didn’t know what I didn’t know. This comes with the territory and should be expected. Some information may only present itself later down the line. So I made sure to make clear to everyone from the very beginning that it wasn’t going to be perfect out of the gate.
Excel: Sometimes we would use excel for what I would call the “quick and dirty” reports to help us along and quickly review data or for the one-off data requests. But here, our goal was to just show the percentage of patients that had a therapist of the same gender or language preference so the dashboard was relatively simple and excel was unnecessary.
Methodology:
Interoperability: In order to match our employee gender to our patient gender, we needed to build out connections between software. This literally meant a single source of truth for every employee ID in every software, and was largely a manual task. We automated where we could, but most of the software we were dealing with didn’t provide an API that allowed for the automated creation of a user. So that meant developing an excel spreadsheet of user software ID matchups otherwise known as a cross reference table. Every person in the organization had an HR user ID. So we started with that and then matched up that ID to every ID they received from the additional software they used. Their EMR user ID. Their Microsoft 365 user ID, etc. And built into the portion of onboarding that dealt with the assignment of software, adding in each ID for future reference. This was crucial for connecting across software. We also developed a workflow so that the data was captured as it was collected. As they were assigned software, we added their new software’s user ID number to their profile.
Data Pipelines and Data Lakes: Our data was stored all over the place so our goal was to move it into a single place we call a data lake. One source of truth and the final destination for all our data. This would prevent duplication, unnecessary data storage and keeps the data honest. Information was copied and pasted from their various sources in assorted fashions depending on what was available. These were called data pipelines. For the robust APIs, we had live data locally. For the once a day refreshed data, we had a copy and pasted refreshed version locally. For the data only available through clickable downloads, we built out either a chrome extension or python selenium navigation tool that would do the download for us. They would also, upon successful transfer to our local database, add additional features/fields/columns to tables in the database as needed. There are more expensive and feature rich options in AWS and Azure for automating and monitoring data pipelines. But I work for a nonprofit and we don’t have that kind of money. Honestly, even if we did, there wasn’t enough interest in data for anyone to spend money on it. So, instead, we used the simple and easily configurable Windows Task Scheduler to run our pipelines daily.
(I don’t have a low-code solution for monitoring our data pipelines currently. Mostly we would just log successes and errors to a single file and then display that on a dashboard.)
Data Dictionary/Catalog: The most important part of any data lake, is its data dictionary/catalog. If the data isn’t described, it’s pretty much useless. People often have different words for the same concept, different concepts for the same word, capture data differently, etc. So it’s crucial to understand the data in depth. A data dictionary describes the fields in a database. It answers the questions of “where is my data, what does my data mean, and how it is collected”. (Most people use .json to store the data dictionary, but use whatever works.) It might contain information like:
which field they connect to on the front end
where in a workflow/s the data is captured
data type (integer, float, date, datetime, multi select dropdown options, single select options, etc.)
It’s relationship to other tables when relevant
refresh rate (is it live, refreshed once a day, or something else)
host software name
other information, like when workflows for data capture were implemented (basically a history of accuracy), needed work etc.
this is usually an iterative process where additional features that need to be added or fields/columns that are unnecessary are discovered and the database is updated accordingly.
This helps data analysts, data managers, and all people exploring the data find the fields they need to develop dashboards quickly. For the most part, we utilized Power BI to do this.
Workflow or Data Issue: When fields are missing and necessary for the analysis, what do you do?
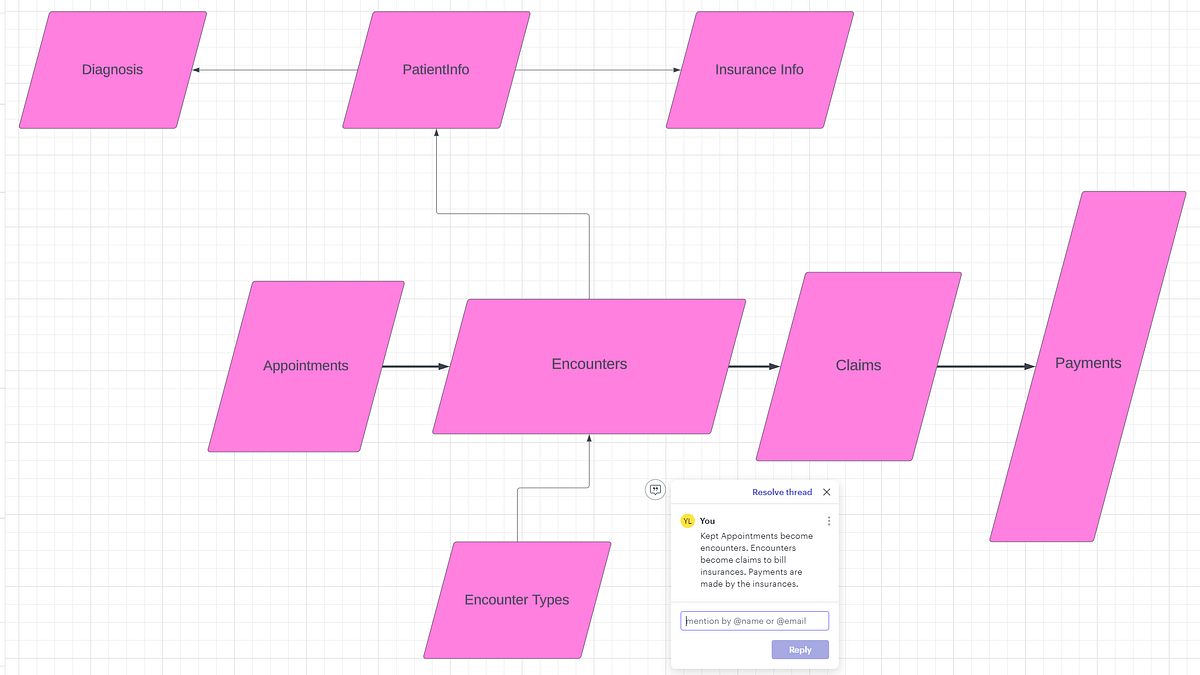
In order to answer that, we needed to answer the following question first. Is this an EMR need or a Data need? Is there data missing from some workflow or is there some label that’s missing from the entire dataset? The former will be dealt with by the internal EMR specialist, while the latter will be dealt with by the data engineer. I needed to work closely with the internal EMR specialist in general to answer questions like these. In our case, we were missing a field telling us if a patient was active. (Actually, there was a field but it was completely inaccurate because no one kept track of it). So we added two fields to our own patient table, most_recent_encounter_type and was_discharged. If the most recent encounter type was a discharge then was_discharged was set to TRUE otherwise FALSE. However, the gender data itself was collected in a free form text field, so we needed to make a recommendation to the EMR specialist to change the field to a single select dropdown. This significantly improved the data quality and reduced errors resulting from attempts at text processing. Understanding the workflow of where and why data was captured, was crucial to making reasonable recommendations for change.Data Modeling: The most important question when building out an easily query-able dataset is which data model to use? If using Power BI, then a star schema is the way to go (Kimball schema, a denormalized approach), if it’s just general reporting, then an Inman schema might be okay. Generally people just go with whatever schema they were given (I’ve added a picture of a classic EMR schema below). But we had to think strongly about where we were adding features to our dataset. Think carefully about where, for example, we would want to add a “most_recent_encounter” field. Do we want it to be an attribute of the encounters table or the patient table? Where would someone look for this? The answer will depend on the business needs but as you saw in my previous answer, in this example, I personally preferred to add it to the patients’ table.
When dealing with multiple data sources, each with their own schema, these questions become a lot more apparent. I tend to keep the data sources for the most part separate unless the request requires some merge. (This usually takes the form of creating a single combined table by concatenating tables on top of one another from each source.) In those cases, it’s crucial to make sure that the granularity and column meanings match up.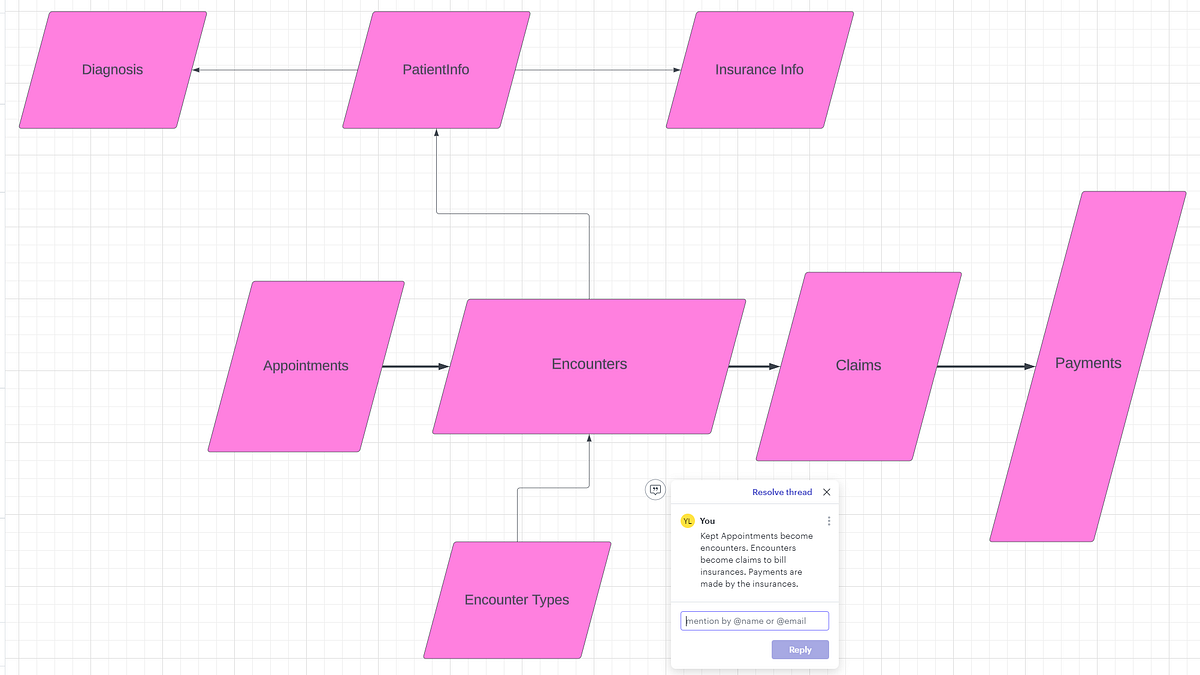
Classic EHR/EMR Data Schema (broadly speaking) Examples for Meaning:
Gender, one source may label Men as “Male” and the other as “M”.
Location, one source might mean Location of encounter, the other might mean the patient’s location.
Example for Granularity: One data source may store a patient’s age for every encounter. Because age changes over time we had to make sure we had the most recent age or calculated the age at the date of the visit from their DOB depending on the need.
In conclusion, we needed to make sure we understood the data we were dealing with.
Finally, with the data all in one place, being refreshed on a regular, automated basis, and directly connected to Power BI, and staff that was interested in helping, I was able to generate a useful dashboard of patient to therapist gender matchups. I was even able to break it down further with additional categories by diagnosis and age group because the features already existed and I just needed to drag them into the dashboard.
In Summary:
If you got this far, congratulations and thank you for reading. I hope it was helpful.
Successful data analytics in the behavioral health, nonprofit space can truelly be achieved by:
Building relationships with leadership,
Developing domain expertise,
Creating a single source of truth connecting the organization’s various software,
Attaching Power BI (or whatever graphing software you want) to that, and building dashboards.
Using that to build stronger relationships with leadership,
etc.
That’s a cycle that will vastly increase anyone’s skills and impact over time. And that’s why we’re here :)
Some Useful References:
I’m providing a link to the SeattleDataGuy YouTube channel and a link to a bunch of useful tutorials (link here). For beginners, I would focus on the following categories in the spreadsheet: SQL, data modelling, data pipelines, data governance, data quality, and data catalogs.
Here’s my favorite YouTube channel for Power BI.
This was super helpful, thank you! I’m currently working at a nonprofit and dealing with a lot of the same issues. Although it’s a much smaller organization than the one you described, I relate so much to all of the issues you mentioned. I’m trying to figure out some simple solutions in the interim because we don’t have the budget for a data analyst, but what we have now is so dysfunctional. Employees track a lot of things on paper still 😱 Thanks for sharing your insights!
Maybe a silly question. but why do you need to know patient provider gender matches?